Data Scraping¶
Data scraping is a technique in which a computer program extracts data from human-readable output coming from another program.
Beautiful Soup (called bs4 when calling the package in Python) is a Python package for parsing HTML and XML documents. This will be used to extract data from HTML pages. Urllib is a Python package that collects several modules for working with URLs:
- request
- error
- parse
- robot parser
The following code block loads these packages and imports BeautifulSoup as soup, which means that we can use "soup" when calling BeautifulSoup functions instead of "BeautifulSoup" to simplify the code somewhat. Also, urllib as "uReq" because the code is only importing the request module. Next, re is imported to facilitate simple usages of regular expressions, very useful for defining search patterns that will be used on the data scraped from the web. Lastly, Pandas as pd providing high-performance, easy-to-use data structures and data analysis tools for Python:
from bs4 import BeautifulSoup as soup # Library for HTML data structures
from urllib.request import urlopen as uReq # Library for opening URLs
import re # Library for regular expressions
import pandas as pd # Library for data structures and data analysis tools
Next a variable is created to store the website URL of interest. The example used here is lifeinformatica.com, a Spanish website that sells computer components. This project will focus on computer central processing unit (CPU) products:
page_url = "https://lifeinformatica.com/categoria-producto/family-componentes/family-procesadores/"
From here the connection is opened and the HTML page from the URl is downloaded:
uClient = uReq(page_url)
Now the html is parsed into a soup data structure. This will allow navigation through the HTML data in a way similar to json data type. After, the connection is closed to the URL (it is important not to leave the connection open):
page_soup = soup(uClient.read(), "html.parser")
uClient.close()
page_soup now holds all the HTML data from the URL. The data of interest is each CPU product, specifically the manufacturer, product, speed, and price. The other infomation contained within the HTML is not of importance to the project right now. By navigating through the HTML structure, it is possible to find the class that holds the data for each CPU product:
containers = page_soup.findAll("div", {"class": "product-inner product-item__inner"})
A very useful way to check the HTML structure of a website is to use the Developer Tools built into most modern browsers. To access the Developer Tools, hit F12 on the keyboard. From here the inspector tool can be used to click on the data of interest. From here, the data is highlighted in the HTML structure:
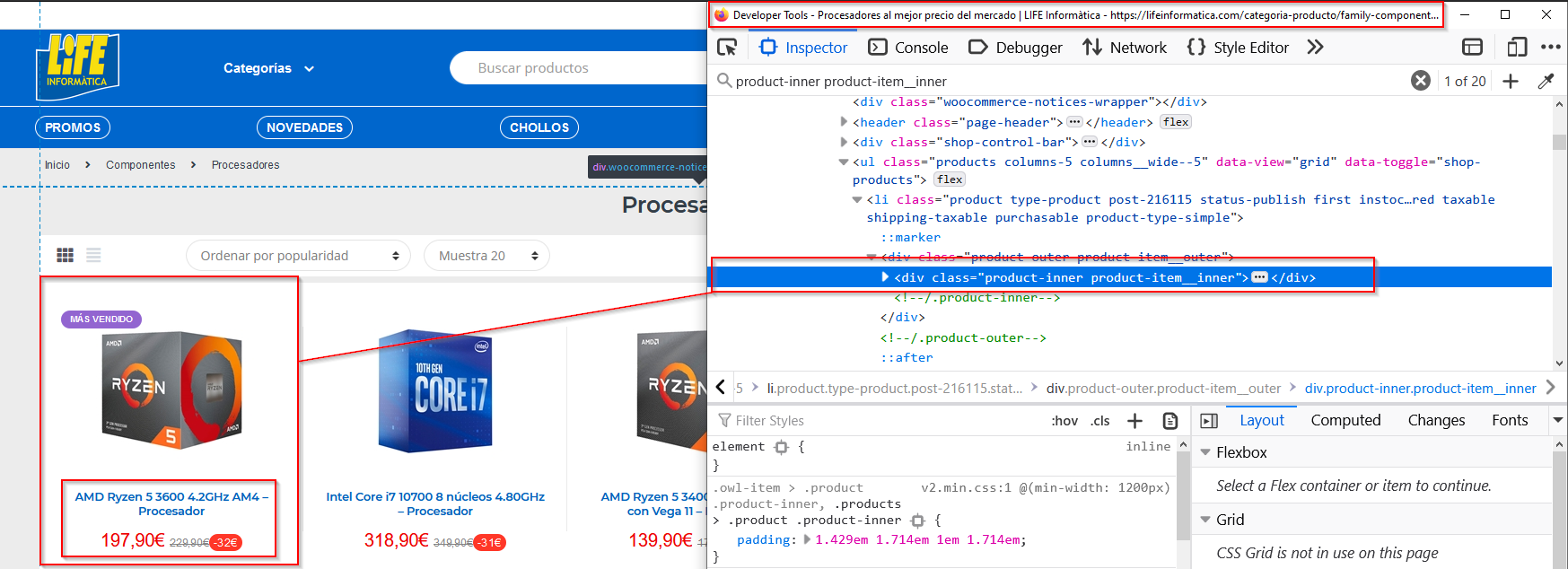
Next, the out_filename is a variable that stores the name of the output file in csv format. The headers variable is used to write to local disk the header of csv file to be written. It is important that the header list is delimited in the same way as the rest of the file:
out_filename = "cpu.csv"
headers = "manufacturer,product_name,speed,price \n"
Next the file is opened and the headers are written to the file. The "w" parameter overwrites any existing content:
f = open(out_filename, "w")
f.write(headers)
Data Extraction¶
Next the actual data extraction from the HTML structure. The data needed is the Manufacturer, Product Name, Speed of the CPU, and the Price. Idealy, the HTML structure would be constructed in a way that all the data needed is already seperated into elements. This is not the case for this website. Here, the data can be extracted by first finding the parts needed. Most of the parts are in the title of each container. From here, strings can be used to carefully pull out the data parts that are needed, in a systematic approach, meaning that it works well for all the CPU products in the webpage.
for container in containers:
#Variables
element = container.findAll("h2", {"class": "woocommerce-loop-product__title"})[0]
split_word = "ghz"
amd = "amd"
intel = "intel"
full_title = element.text.lower()
#Manufacturer
manufacturer = element.text.split(" ", 1)[0].lower()
#Speed
if manufacturer == amd and split_word in full_title :
speed = full_title.partition(split_word)[0].split(' ', 4)[4]
if manufacturer == intel:
speed = re.search("([^\s]+)"+split_word, full_title).group(1)
#Product Name
if manufacturer == amd:
product_name = re.search(manufacturer+"(.*?)"+speed, full_title).group(1)
elif manufacturer == intel and "núcleos" in full_title:
product_name = re.search(manufacturer+"(.*?)"+"núcleos", full_title).group(1)[:-3]
#Price
price = container.findAll("span", {"class": "woocommerce-Price-amount amount"})[0].text.strip().replace("€", "").replace(",", ".")
#Write the data into respective columns
f.write(manufacturer + ", " + product_name.replace(",", "|") + ", " + speed + ", " + price + "\n")
# Lastly, the file must be closed
f.close()
Accounting for Upper and Lower Case¶
Often it is the case that data is not in a perfect state. In this example, some key words are written in different cases, such as "GHz" or "GHZ". To overcome this, all the text that searches are carried out on are made lower case, using .lower(). This is just one example of how to deal with anomalies in data scraping.
Checking the Output¶
Lastly, the head() function is called to inspect the first 5 rows of the csv file that was closed in the above line. From this it is clear that the data has been scraped, parsed and ordered into the desired headers. For this, the head() function is very useful for quickly testing if the object has the right type of data in it:
data = pd.read_csv("cpu.csv")
data.head()
Conclusion¶
This project demonstrated how to scrape a website for data using Python and Beautiful Soup. The code starts by defining the website address of the data needed. Then this data is stored locally in a CSV file. Next a method to inspect the webpage manually is shown using the browsers Developer Tools. From here the data is parsed to pull out the useful information, this occurs in the for loop section of the code. Lastly the file is closed and the data within the CSV file is checked to see if it has the right type of data in it.