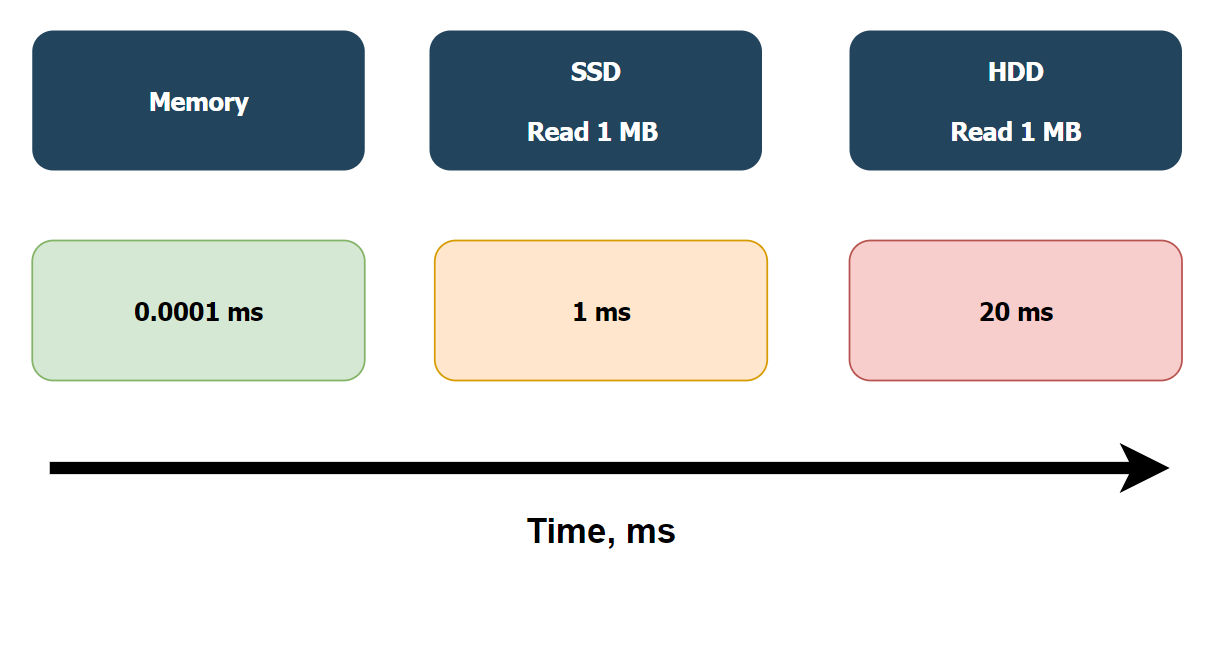
B-tree Index¶
As the name suggests, data in a B-tree index is organised in a tree like structure, with a root and nodes. The root number is roughly the middle value of the dataset, from here the nodes split to the left and to the right of the root. The smaller numbers split to the left and the larger numbers split to the right. This pattern continues until the bottom is reached, the point at which all the data is accounted for.
For example, if the root has a value of 100, the node may split on the left side at 75 and the right side at 125. Each of these nodes will split again, so the left 75 will split to the left at 63 and the right at 87. This pattern continues at each level of the tree, an example of this can be seen below.
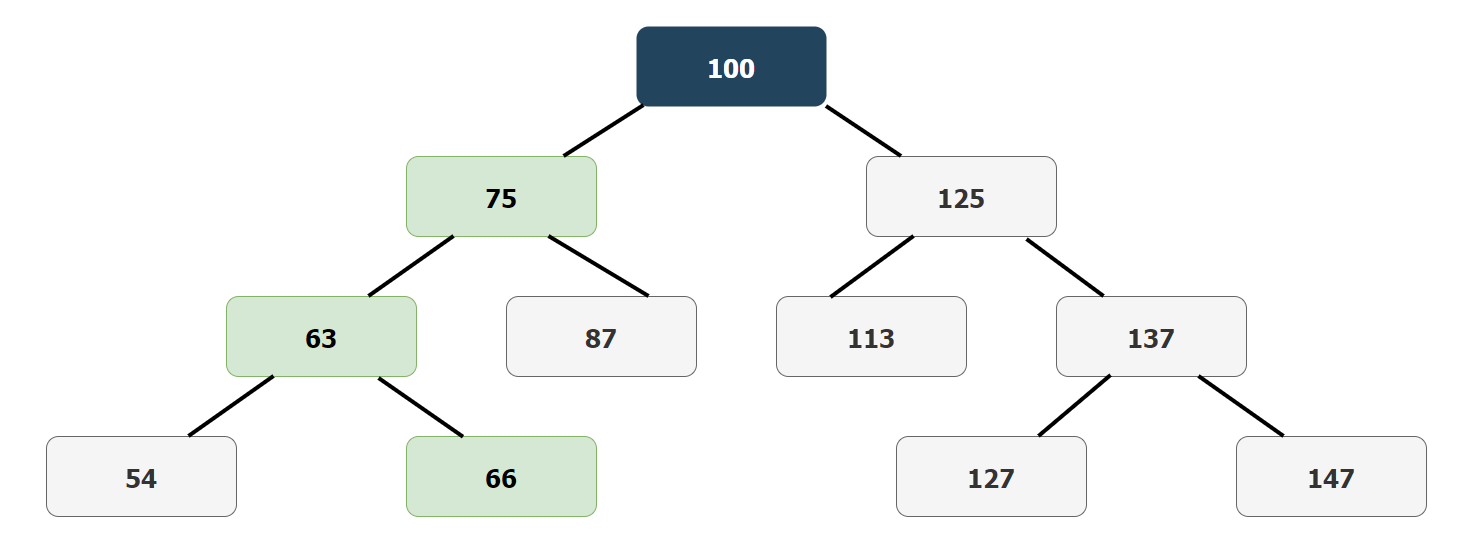
If the value 66 is needed, it would take three comparisons to reach, as seen in the above B-tree index example. From the root at 100 to the left node at 75, then to the left at 63, and finally to the right to reach 66. This path is indicated above in green.
The B-tree index is one of the more common indexes. In PostgreSQL it is the default index. It is useful when there are many uncommon or unique values in a column, which is known as high cardinality.