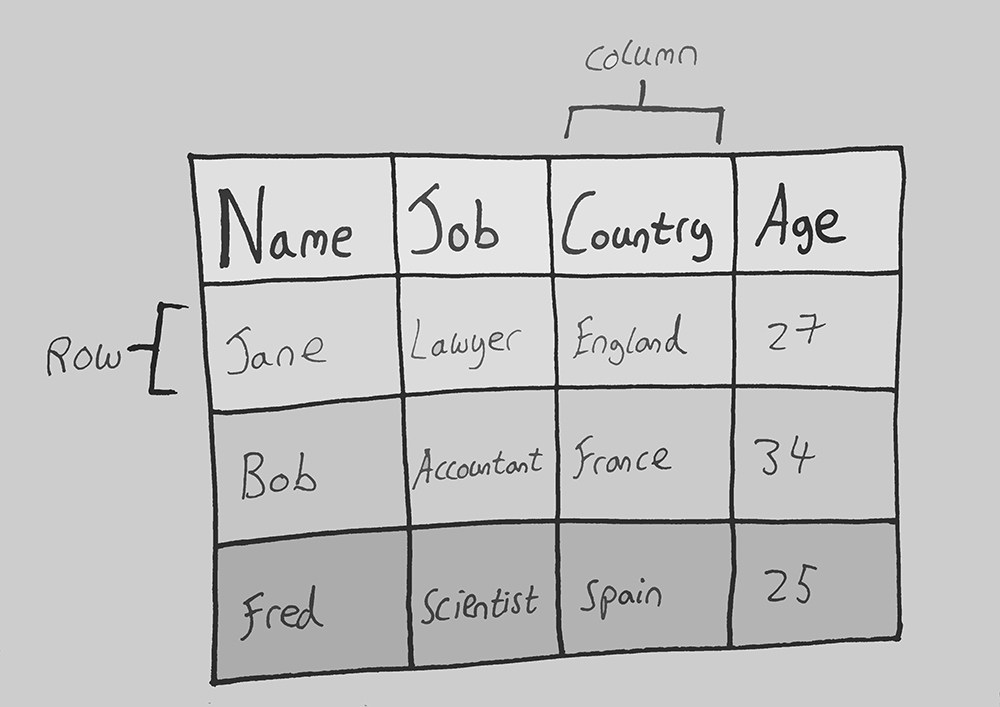
What is a Table?¶
A table contains data. A table is used to organise data so that it can be manipulated and analysed in various ways applicable to the questions being asked of the data. A data table can be broken down further to its constituent parts:
- rows
- columns
Each row in a table represents one entry, in the sketch below, the row entry from left to right is, Jane, Lawyer, England and 27. Each column in a table represents a feature, the below example shows the "Country" feature. It is important to note that each entry in the column is of the same datatype.