Conan Mercer Site Reliability Engineering Leader
Amazon Web Services Cloud Development Kit - A Strategy for Infrastructure as Code
22 Sep 2024 - Conan Mercer
Problem Statement
CloudFormation (Cfn) templates, while effective, can become time-consuming to manage and are usually written in a language that differs from the application’s service code. Deployment is often handled through a third party build server (such as TeamCity), which introduces extra components and associated costs. This post explores the use of Amazon Web Services Cloud Development Kit (CDK) and GitHub Actions as potential alternatives, providing a more cohesive, service-driven approach to infrastructure. By aligning infrastructure code with service development, this approach aims to improve workflow efficiency and simplify deployment processes.
Note: A repository of code has been written in-conjunction with this post. I have written examples to accompany this post in C Sharp and Python. The code is functionally the same, however written in two different languages to provide proof of concepts in multiple languages.
The accompanying code to this post resides on my GitHub - it can be viewed from hereA Case for Amazon Web Services Cloud Development Kit
Amazon Web Services Cloud Development Kit
CDK is a software development framework used to model and provision cloud application resources in AWS. It can be used with 5 programming languages:- Python
- Java
- .NET
- GO
- TypeScript
Advantages over Alternatives
Advantages over Cloudformation Templates
Cloudformation (Cfn) is wonderful for small scale infrastructure deployments, but can quickly become unsuitable for large enterprise cloud environments. The main reason for this is because Cfn is not programmatic. Cfn typically results in a massive amount of JSON or YAML code, that needs to be fed into TeamCity (or similar build servers) to request, maintain, provision, and destroy stacks. CDK outputs Cfn, so the end result is the same, however using CDK can simplify, automate, and organise code more efficiently. It also comes with more benefits which are discussed in detail throughout the rest of this post.
Advantages over Terraform
Terraform is an infrastructure as code tool. Terraform can be used with different cloud providers, which is a better choice if the system architecture uses multiple cloud providers, or if in the future it is likely that the system will be migrated to another cloud provider other than AWS. CDK is built by the AWS team specifically for AWS Cloud, this means that CDK is supported to the fullest extent possible (see subsection 3.1 for an expanded argument). Terraform is free to use but costs can occur for additional capabilities. CDK is totally free and is much more likely to remain free as it is a tool for AWS to get customers on board to their cloud offerings. Terraform is written in HashiCorp Configuration Language (HCL), whereas CDK can be written in the same language as the application/services, lowering the developer barrier for adoption.
Native CDK Advantages
Time to develop. Writing Cfn templates and using, for example, TeamCity to deploy them, is laborious. It works, but it takes more time to complete a development cycle. When changes are made locally, there is no simple method of checking template validity. It is true that the AWS CLI can be used to send the Cfn template to AWS, which then returns if a template is valid, but this needs to be setup. With CDK, by running cdk synth in the command line the developer can immediately observe if their code changes are at least valid. Another useful command is cdk diff. This compares differences between the current state of stacks in the local CDK app against deployed stacks. This command is of great use when developing, and also when identifying if changes desired are changes that will actually be deployed. It is also very powerful when refactoring IaC. Post refactor, this command can be run to ensure that the underlying cloud resources have not changed.
CDK Application
CDK Applications are comprised of various components. It is a collection of one or more Stacks, each Stack is composed of one or more Constructs. Ultimately, the output of a CDK app is a Cfn template, it is the journey CDK takes the developer on that makes this output achievable in a programmatic, reliable, and efficient manner. An example is shown in Figure 1
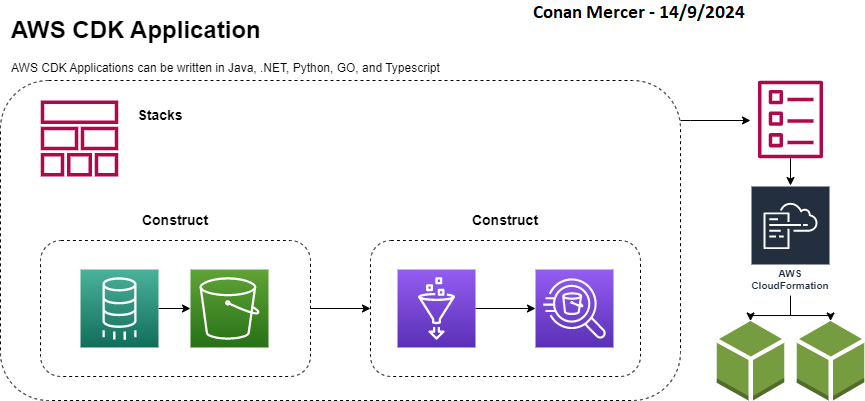
Constructs
Constructs in CDK are organised into 3 levels. With each level comes an increase in the level of abstraction. The highest level of abstraction (level 3) is easier to configure and requires less expertise, conversely Level 1 constructs offer no abstraction and are therefore more challenging.
Level 1 Constructs
Level 1 (L1) constructs, are denoted by Cfn and offer no abstraction. They are useful when a deep knowledge of AWS is held by the developer, and complete control over the deployed infrastructure is required. For example, CfnNatGateway is a L1 construct that maps directly to AWS::EC2::NatGateway in a Cloudformation resource. If a resource exists in AWS CloudFormation, it will be available in CDK as an L1 construct.
Level 2 Constructs
L2 constructs provide some abstraction, for example the construct s3.Bucket creates an S3 bucket with associated policy objects. The main difference between L1 and L2 constructs is that L2 constructs provide intelligent default property configurations, notably security settings. For this reason they are the most used constructs.
An example of L1, L2, and L3 Constructs for creating S3 buckets can be found hereLevel 3 Constructs
L3 constructs provide the highest level of abstraction. They can contain a collection of resources, not just one, and can be used to deploy in some cases a completed architecture solution. For example the ecsPatterns.ApplicationLoadBalancedFargateService class provides a Fargate service running on ECS with an included load balancer.
Stacks
Single Stack
At some point, the CloudFormation template generated by a single Stack will become too large, reaching AWS limits. When this happens, the project will need to be split into multiple Stacks. Updates to stacks will take longer, as AWS must process the entire stack for any changes, making it harder to pinpoint what has changed. The output of cdk diff will become difficult to read, as developers will have to sift through many lines of output to find the relevant differences. In large applications, a small issue in one part of the stack (such as a reference to a deleted policy or IAM role) can block the entire stack deployment, potentially delaying critical changes from being deployed to production.
Multi Stack
A multi-stack approach addresses many of the problems seen in single stacks, but introduces some new challenges, such as more frequent updates across multiple stacks and handling cross-stack dependencies. If a resource is shared across multiple stacks, removing it can be tricky. However, on balance, using multiple stacks is generally the best way forward.
Stack Best Practices
- Put stateful resources in their own stacks. This avoids an ”atomic block” where making a change cannot disturb another stack.
- Always provide the account and region for every stack that is being created.
- Refactor the code often, using cdk diff to ensure that the existing deployed stack wont change.
- Snap-shot test the stack often
- Avoid having more than 7 constructs per stack, anything more usually means a refactor to avoid complicating the stack
Infrastructure and Tooling
Infrastructure and Application Code
If infrastructure code is written in the same language as the application and services code, this simplifies the architecture of the entire system. The benefits here should be obvious, but I expand on some themes in the following sub sections.
Collaboration and Team Productivity
Option 1: Everything in one repository
Having IaC, deployment, and application code reside within the same repository is ideal because it enables all engineers involved in the project to have the same visibility, and hopefully innovate together. In theory it can help to facilitate faster development as silos are reduced between infrastructure and application code.
Option 2: Separated application code pipeline
If it is not ideal to have IaC and application code to reside in the same repository, and silos are actually desired, this can be achieved. This would decouple IaC and application code by sorting them into separate repository’s. Both the service and IaC can still be written in the same language.
GitHub Actions Deployment
Because the IaC and application can reside in the same repository, and the repository is on GitHub, all deployment code can also reside in the same repository by using GitHub Actions to deploy infrastructure. This is very powerful because at this point all the IaC, application code, service code, and deployment code are in the same repository. This also means that external deployment software such as TeamCity can be done away with, including their expensive licenses. Github Actions is free until a point, but costs do occur so it is not a free alternative, but the benefits outweigh the disadvantages. With very little code, a GitHub Action can setup AWS credentials, configure the environment, install necessary dependencies, run tests, and then deploy the stack using AWS CDK. An example is shown in Figure 2.
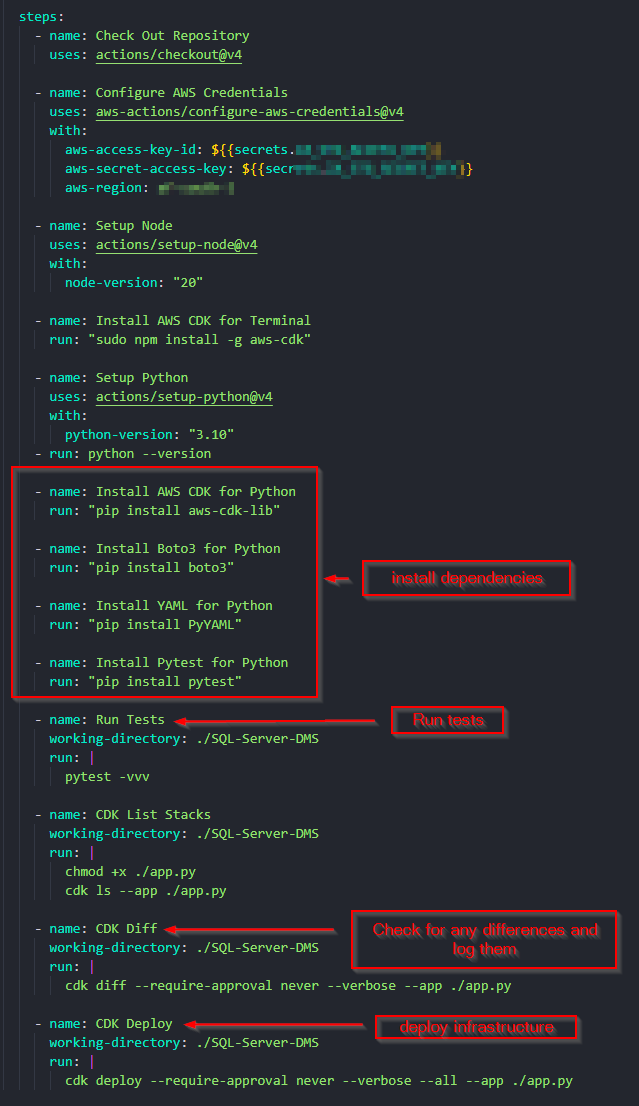
GitHub Action Authorisation
Although using long lived keys or access ID is common practice, it is far from ideal. A more secure approach is to use OpenID Connect (OIDC). OIDC allows GitHub Actions workflows to access resources in AWS, without needing to store the AWS credentials as long-lived GitHub secrets. More information on implementing this can be found here
Version Control and Tracking
With IaC, infrastructure configurations can be stored in Git version control. This brings transparency, making it simpler to track changes and revert to previous versions if needed. When this is coupled with GitHub Actions for the deployment of infrastructure, not only can the infrastructure change be tracked, but also the tooling used to actually deploy the change. This should result in enhanced debugging compared with traditional build servers such as TeamCity, which do not make it easy to track changes to build configurations.
In the event of a disaster, because the infrastructure code, the deployment pipelines, and the application/service code are all contained within the same GitHub Repository, a true recovery from nothing is possible, and can be automated and tested regularly to simulate how quickly a recovery can occur from ground zero. Imagine a brand new AWS Account that needs to be provisioned exactly as an older, compromised, AWS Account.
Because the IaC and deployment pipelines are both versioned, they can be subjected to peer review. This is an often overlooked aspect of deployment pipelines. With TeamCity, it is very difficult to subject a pipeline change to peer review. This causes two major issues:
- Only the creator of the change typically is aware a change has been made
- Peers cannot review the change for possible errors and have little to no opportunity to improve the code of the committer
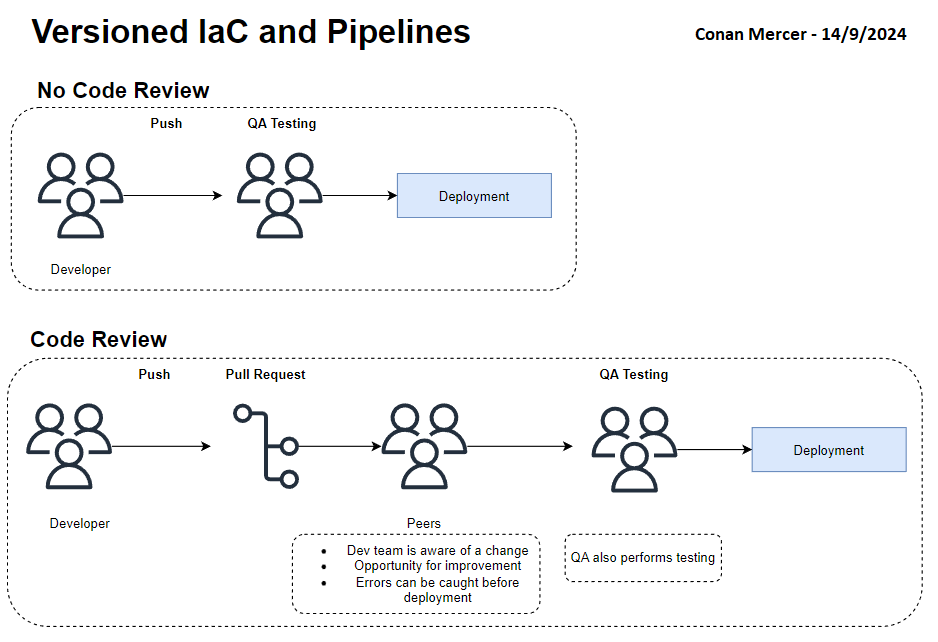
Having both the application/service and IaC versioned equally is a big improvement. The version could also be tagged with the git hash of the commit that caused a version change. That would mean that a version can be tied back to a specific commit. For example a docker container could be tagged in ECR with the commit hash, it would then be very trivial to look at what changed between two versions of a docker container. This would make debugging docker container issues easier.
Testing and Validation
CDK code is testable, just the same as standard software development testing works. CDK apps use three types of testing categories:- Fine-grained assertions
- Snapshot tests
- Integration tests
Fine-grained assertions can be used to test for regression. They work by testing the output (Cfn template) for example ”does a resource have a specified property with a certain value”. They can be useful in test driven development, by writing the test first and then making it pass by writing a correct implementation in CDK.
Snapshot tests can be used when refactoring CDK code. This tests that the refactored code is not going to change at all the state of the already deployed infrastructure. It does this by comparing a synthesised template (the new refactored template) against a previously stored baseline template, the template currently deployed for example.
Once tests have been written, they can be included in CI/CD builds and infrastructure deployments. Depending on how strict the deployment needs to be, the tests can be run before any deployment occurs, and would fail a deployment if the tests fail for any reason. This adds a layer of safety and builds confidence when deploying changes to infrastructure. If for lower environments it is acceptable to not be as strict, the tests could be triggered to run only on Pull Requests. An example of a pipeline is shown in Figure 4.
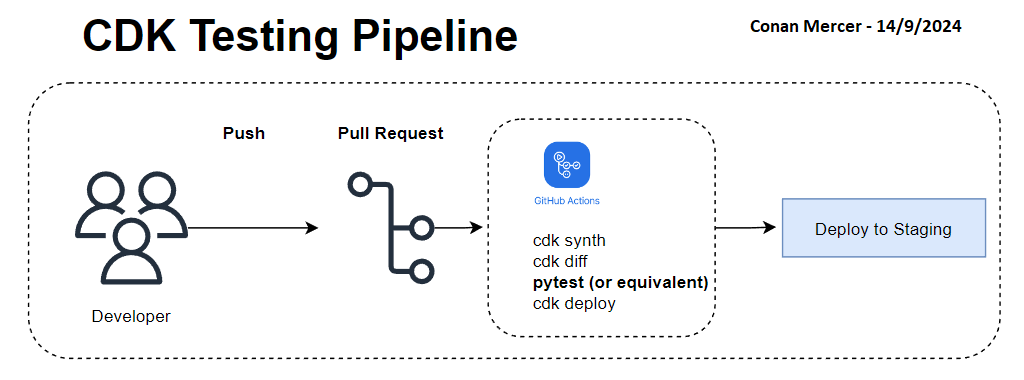
Integration testing is also possible with CDK, I will not go into detail here, but infrastructure can be deployed into 3 different regions and tested, this is very useful when planning and testing for disaster recovery, and by deploying (temporarily while testing) into multiple regions can uncover a lot of mistakes that would not normally be caught until a real world disaster.
Code Organisation for Large Projects
A CDK codebase needs to be well organised, and scale well. In this context, scaling means that the IaC doesn’t become hard to navigate, extend to multiple teams incoherently, and does not become slow to develop with or hard to on board new colleagues with.
Factories for Consistent Patterns
Abstract factories are common, well known, design patterns in software engineering. These can be used to promote code reuse and simplify the process of managing constructs.
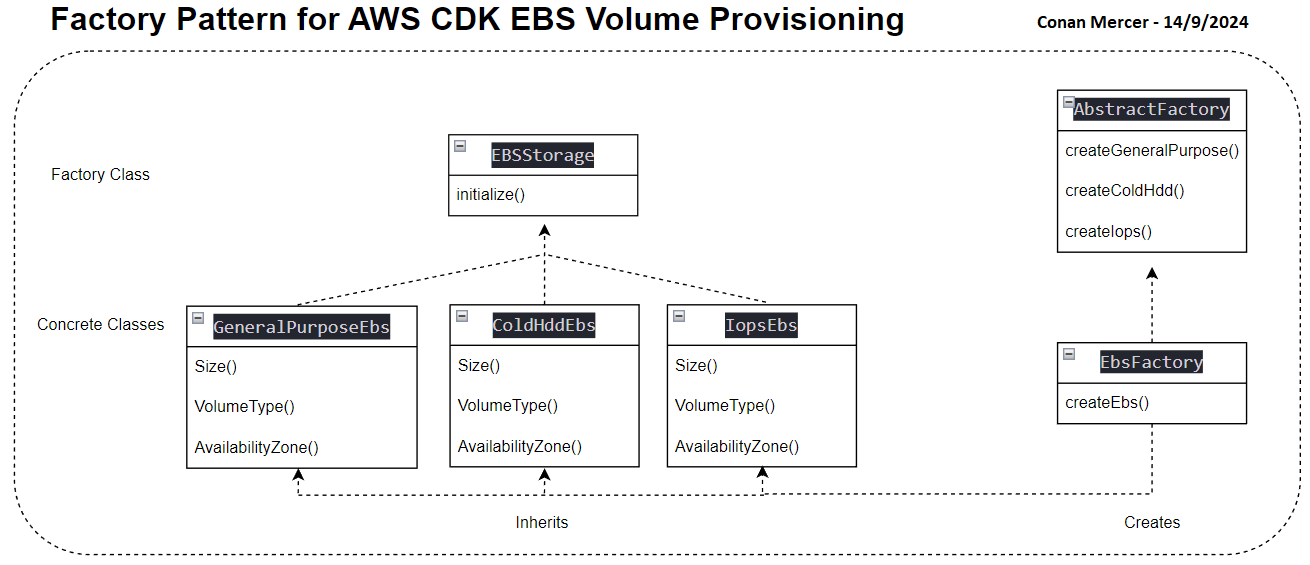
Take for example provisioning EBS volumes. To provision EBS volumes efficiently, a design pattern that encapsulates volume creation logic can be used. The code defines an abstract base class called EBSStorage and several subclasses (GeneralPurposeEbs, IopsEbs, and ColdHddEbs) that represent different types of EBS volumes. Each subclass implements the initialize method to create specific EBS volumes with tailored properties, such as volume size and type.
An abstract factory, AbstractFactory, defines a method for creating EBS volumes, while EbsFactory provides concrete implementations based on the desired volume type (e.g., gp2, io1, sc1). This pattern simplifies the creation of EBS volumes by encapsulating the setup logic, promoting code reuse, and ensuring adherence to best practices.
The CdkEbsStack class demonstrates how to use this factory to provision and initialize an EBS volume in a CDK stack. By selecting the volume type through the factory, developers can easily manage and configure EBS resources in a consistent and maintainable manner. As shown in Figure 5, the Factory Pattern is used to create and initialize different types of EBS volumes in AWS CDK.
View the Python code for the CDK EBS stack on GitHub by following this link and the C Sharp code following this link.
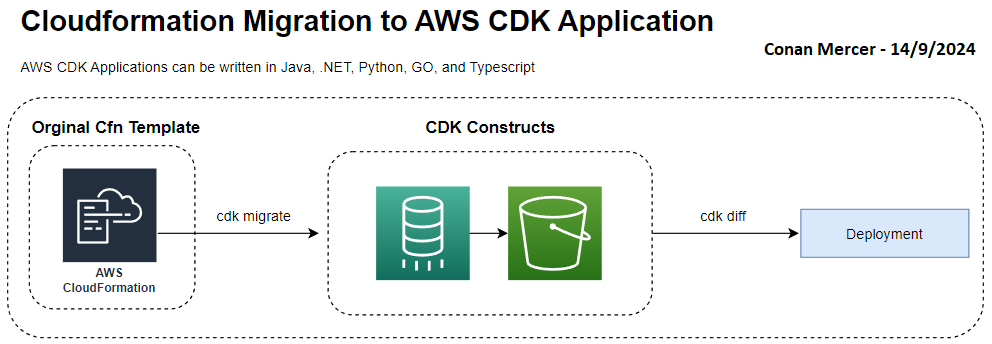
Migration from an AWS CloudFormation template
When migrating workflows and IaC, time to develop, foresight, and costs need to be addressed. Ultimately if the time taken to complete a migration is too long, or if it costs too much money, it may not be the best route forward. The corollary argument is that accumulating technical debt, the risk of a technology stack becoming too old, is a risk that is often overlooked. With that said, here are some thoughts on how a project can go about minimising these risks as much as possible.
For large enterprise projects that have already been written in Cfn templates, it is possible to migrate those Cfn templates into CDK code. The AWS CDK CLI can be used to migrate from the following sources:
- Deployed AWS resources
- Deployed AWS CloudFormation stacks
- Local AWS CloudFormation templates
This strategy can be used to get a CDK migration off the ground. It will try to create a CDK stack on a best effort basis, so while not foolproof it will go a long way to assist. Once the Cfn template has been migrated into a CDK app, normal CDK development and modification can occur. To test the new CDK version of the original Cfn template, cdk diff can be run locally to ensure no changes have been made to the underlying infrastructure.
This feature is experimental, and all 5 of the programming languages supported by CDK can be used. For example to convert an API Gateway Cfn template stack into a CDK app written in Python code, the following command can be run:
cdk migrate --from-path "./gateway.json" --stack-name "myCloudFormationStack" --language python
Integrating AWS CDK with Application Code for Real-Time Infrastructure Monitoring and Synchronization
The following is a more advanced use case of CDK with application and service code where there is automated communication between both. In short, the application or service can know when there is a problem with the infrastructure it is running on and make adjustments to correct itself. I will outline a rough example to demonstrate this possibility. Actual implementations can take a different approach but this is useful to gain a clearer picture of the concept. This is accompanied by Figure 8
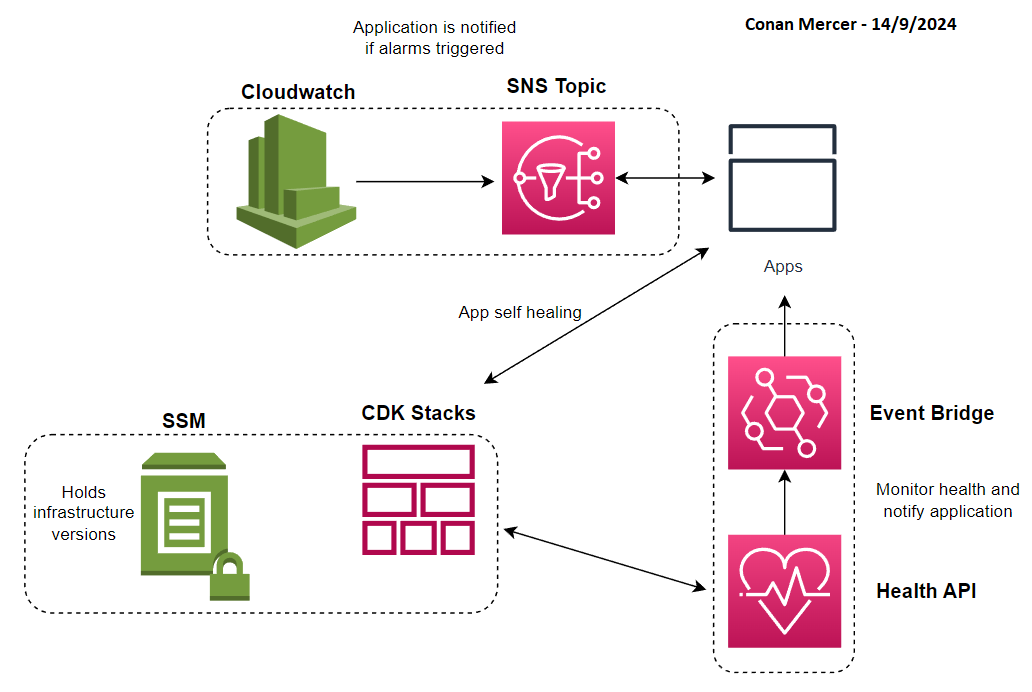
Using CloudWatch Alarms and SNS for Notifications
CloudWatch Alarms can be created, which the application or service can listen to in case of an infrastructure issue via SNS notifications. The application can subscribe to the SNS topic using AWS SDK or other methods to receive notifications when an alarm is triggered.
Using AWS Health APIs and EventBridge
AWS Health APIs can be used to monitor CDK derived AWS infrastructure health. EventBridge rules can then capture AWS Health events and notify the application.
AWS Systems Manager Parameter Store for Syncing Versions
The infrastructure version can be stored in SSM Parameter Store using CDK, this would allow the application to ensure it is synced with the correct infrastructure version. The application can query the parameter store to validate infrastructure versions using the AWS SDK.
Application-Driven Self-Healing
If the application detects issues with the infrastructure, it can trigger self-healing by updating or re-deploying specific parts of the CDK stack.
Example Scenario Auto-Restarting an EC2 Instance on Failure
Suppose an application is running on an EC2 instance. If the instance becomes unhealthy (e.g., due to high CPU usage, disk space exhaustion, or a process crash), the application could experience downtime. A self-healing solution could automatically detect this issue, stop the unhealthy instance, and launch a new one or restart the same instance.
Summary
CloudWatch Alarms and SNS can be used to notify the application in real-time whenever infrastructure issues arise. EventBridge captures AWS Health events, such as planned maintenance or outages, and relays them to the application. To ensure consistency, the infrastructure and application versions can be synchronized using SSM Parameter Store. Additionally, self-healing mechanisms can be implemented by allowing the application to trigger infrastructure automation via AWS CDK in response to detected problems.
Conclusion
In conclusion, AWS CDK offers significant advantages over traditional CloudFormation templates and Terraform. Its use of general purpose programming languages such as C Sharp and Python allows developers to leverage existing coding skills, create reusable constructs, and benefit from familiar software development best practices like version control, unit testing, and refactoring. This flexibility accelerates infrastructure development and reduces errors by enabling the use of logic, loops, and conditions within the code, which can be more cumbersome with JSON or YAML based CloudFormation templates.
One of the key benefits of CDK is the ability to synchronize application and infrastructure code within the same project, enabling both to be versioned together. This ensures that any changes to infrastructure are consistently aligned with the corresponding application or service updates, simplifying deployment workflows and minimizing potential issues from misaligned versions. While Terraform provides cross-cloud capabilities, CDK’s tight integration with AWS services and its developer-friendly approach make it an ideal choice for AWS-centric organizations, offering enhanced productivity, scalability, and maintainability.